Mean Time to Recovery (MTTR)
En combien de temps retrouvez-vous un service normal ?
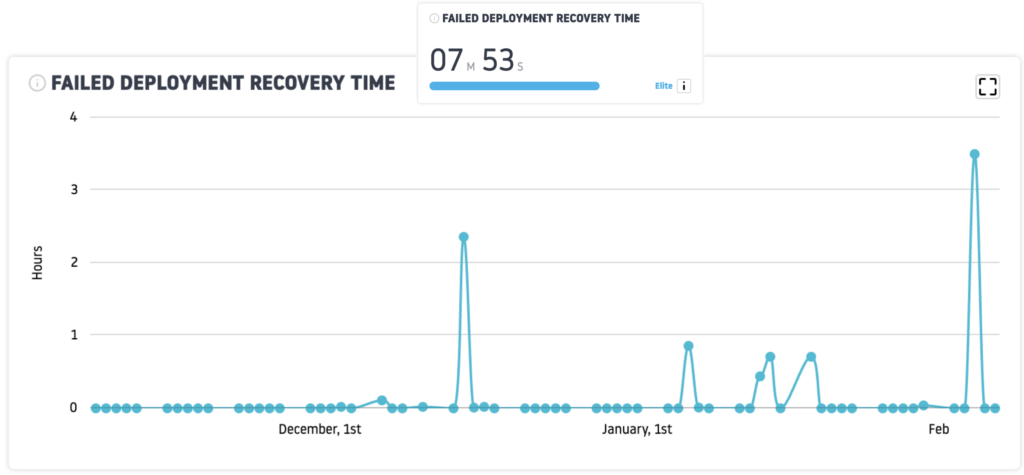
Qu'est-ce que le Mean Time to Recovery ?
Le Mean Time to Recovery mesure le temps moyen nécessaire pour restaurer le service après un incident en production. C'est le quatrième indicateur DORA qui évalue la résilience de votre équipe. Un MTTR court signifie que l'équipe détecte, diagnostique et résout rapidement les problèmes. Un MTTR long expose vos utilisateurs à des interruptions prolongées.
Pourquoi l’utiliser ?
- Mesurer la réactivité de votre équipe face aux incidents de production.
- Évaluer l’efficacité de vos processus de détection, diagnostic et résolution.
- Identifier si vos investissements en observabilité et automatisation portent leurs fruits.
- Rassurer les parties prenantes sur votre capacité à minimiser l’impact des incidents.
Méthode de Calcul
Le MTTR est calculé en mesurant le temps moyen entre la détection d’un incident et la restauration complète du service.
MTTR = Moyenne(Date de résolution - Date de détection de l'incident)
Benchmarks DORA
- Elite : Moins d’une heure
- High : Moins d’un jour
- Medium : Entre un jour et une semaine
- Low : Plus d’une semaine
Les patterns courants observés
Récupération rapide et constante
Le MTTR reste bas et régulier. L’équipe dispose d’outils de monitoring efficaces, de runbooks clairs et de procédures de rollback éprouvées. Les incidents sont traités avec méthode et rapidité.
Temps de récupération en hausse
Le MTTR s’allonge progressivement. Cela peut révéler une complexité croissante du système, un manque d’observabilité, des connaissances concentrées sur quelques personnes (bus factor), ou des procédures de résolution inadaptées à l’échelle actuelle.
Forte variabilité
Certains incidents sont résolus en minutes, d’autres en jours. Cette dispersion signale des niveaux de préparation inégaux selon le type d’incident. Les résolutions rapides reposent probablement sur de l’automatisation, tandis que les longues mobilisent du diagnostic manuel.